Repo

Problem definition
We would like to build a question tagging API for Stackoverflow. In this process, on top of classic Natural language processing tools,
we will use MLflow and Streamlit to realize our API.
Note that this is a very special type of data. Indeed, our intuition first says we will not use all of the available features to us
as only some of them will do the trick. Furthermore, given the nature of the data we would like to limit number of features, otherwise
we will have very long computing times.
We are in a supervised learning situation as Stackoverflow provides us with already labeled data. But we will also use unsupervised learning techniques
for curiosity to evaluate the possibility of our models to create topic clusters
Retrieving our data
We will need to retrive our data via SQL requests on stack explorer. We don't need a good knowledge of SQL to realize, but we have some constraints to be aware regarding the platform and the data
- - We can only request 50,000 posts per request
- - All questions do not have the "same value". We would like to keep meaningful and popular questions only
- - Not all features are going to be useful in this process
We adress the above mentioned challenges by taking the following decisions:
- - We decide to download the most viewed questions for the last 4 semesters
- - We will mainly focus on the 3 features of the database: Titles and Posts as features, and Tags as Target
- - Not all features are going to be useful in this process
Here is the SQL request that we made to retrieve the data:

Preprocessing our data
We are going to apply similar preprocessing and tranformations to Tags, Title and Post. Let's start with the target Tags
Tags
Given the structure of the Tags column, there is some specific transformations to be done here. In this paragraph, we will focus on core NLP preprocessing. For more details, about other transformations please on Tags go on the Github repo on top of the page.
Chart below describes the distribution of our tags across the database:
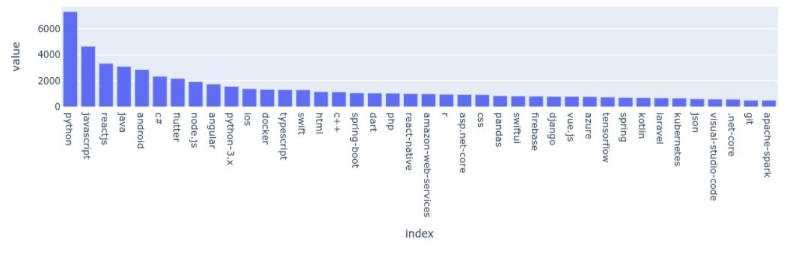
We decide to select the most common tags in our database only to prevent some overfitting already, and reduce size of tags database. (c.23,000 tags otherwise for 200,000 datapoints...)
Titles & Body
In this section, we start the real natural language preprocessing. The steps decribed in this section will be very similar to the one we apply in Body column: tokenize, remove stop words, lemmatize and then rejoin. We write our own methods and use tensorflow too. Please have a look into the repo to see more details about it.
Note that we decide to leverage the power of the 'Title' column: by nature, the user has to be very clear and concise to help the users seeins the post understanding the core problem quickly. That is the reason why, we decide to create a new column called "Post" that is weighted merger between Body and Title: we copy Titles 4 times and Body one times. That is going to increase the weights associated to Title words.

Machine Learning Models
Train/Test split
We use sklearn methods to split our data into test and train data. Note that we are going to try both TF-IDF and BoW structure for our models. We will use TF-IDF in our supervised learning models, and BoW in our Unsupervised learning models.
We decide to limit the number of words in TF-IDF to make our models run faster and avoid noise that could be given by words that are extremely rare.

Supervised Learning
We run first a PCA to select the most important features in our TF-IDF model and reduce dimensionality.
We will use MultiOuputClassifier as a way to run our models, but an approach with the right parameters in OneVsRest() will be 100% equivalent. Below we show the models we are going to try.

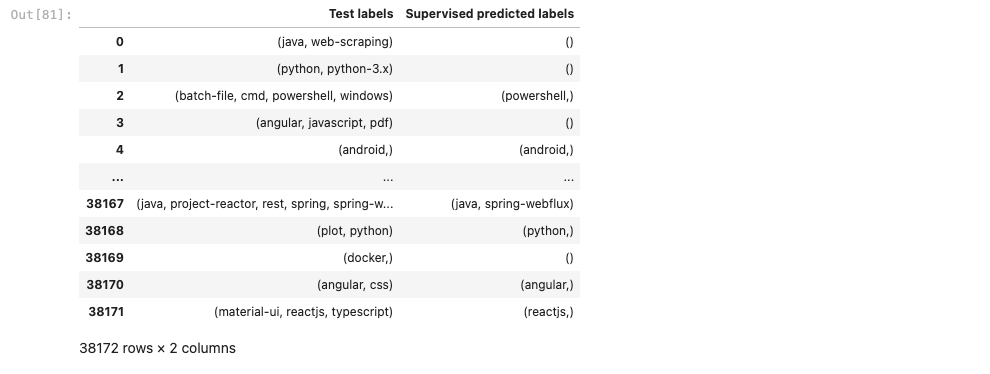
We have run a GridSearchCV to fine tune the main parameters of our selected model, which is SGDClassifier with a Hinge loss and L2 regularization. Note that the hypertuning has very little impact on the results of our model. Below are the results of the output.
Unsupervised Learning
We are going to use Gensim's implementation of LDA, which allows use to parallelize the workload and reduce computation time dramatically.
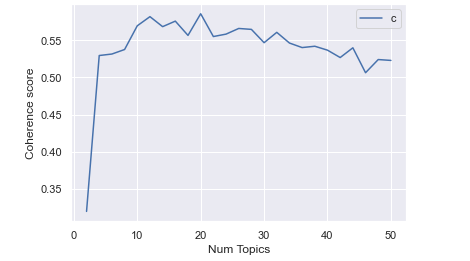
We have to provide the expected number of topics in the corpus to run the algorithm. We run a for loop to find the optimal num_topics considering that we are using the coherence value to find the optimal number of topics.
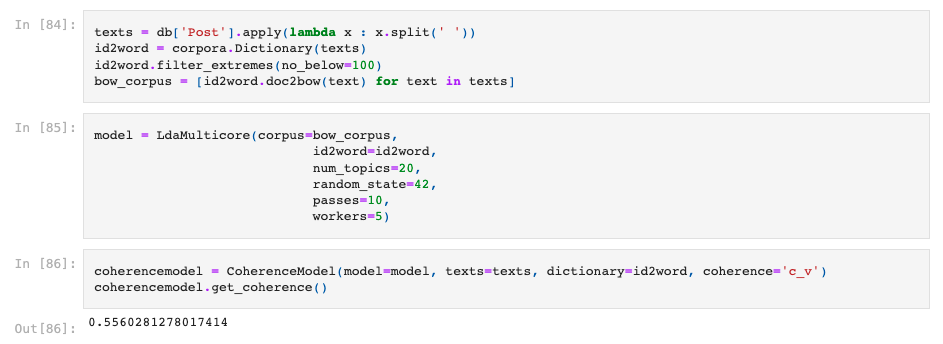
Naturally, given the nature of the project here, we expect results of the Unsupervised Learning to be quite low compared to supervised learning. Here are the results:

Neural Networks and Keras Word Embeddings
We will use words embeddings in this section. Note that we use our own word embeddings to our own neural networks. We think it could be a good idea to try Word2Vec combined with this model as results will probably be better.
We use Keras intro to Neural Networks to structure our model. Here is its structure:

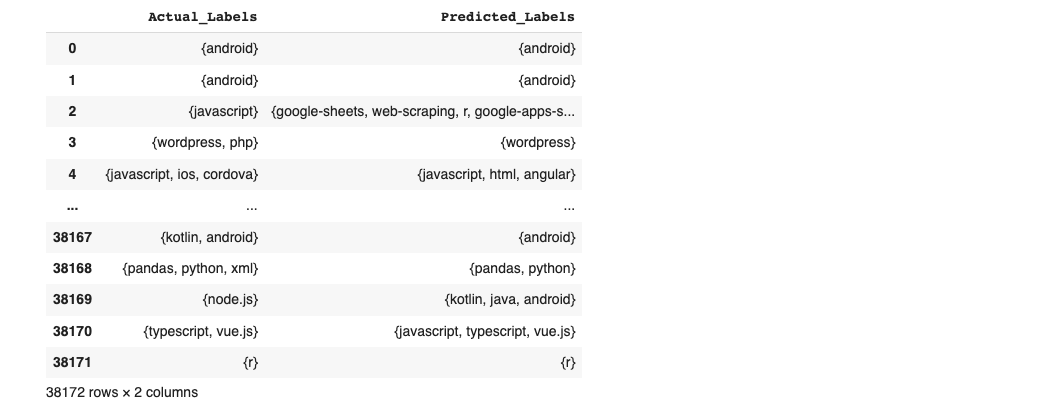
After running our model, here are the results:

Trying Hugging Face
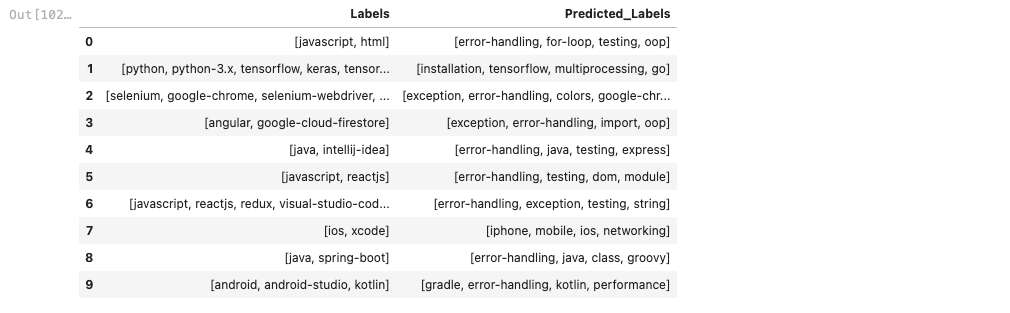
We decided to try Hugging Face Zero shot classification, just for curiosity. While we think the results are promising, there is more work to be done. We just run our code for the first 10 observations of our database
API: MLflow and Streamlit
We have published our API via MLflow and Streamlit, which are 2 very simple and free solutions to do so.